发布日期:2024-10-09 17:40 点击次数:96

在本文中大奶女,咱们将探讨孤苦于任何用具的中枢 MLOps 原则。这些原则旨在匡助咱们想象出健壮且可膨胀的分娩级机器学习系统和架构。
自动化或操作化
版块端正
实际追踪
测试
监控
可复现性
当先,咱们来接洽自动化(操作化)的基本因素。
自动化或操作化
为了实施 MLOps,大大量应用系统会阅历三个中枢档次的缓缓演进,从手动操作到齐备自动化:
手动过程:在开发机器学习应用的早期,过程凡俗是实际性和迭代性的。数据科学家手动引申每个管谈的措施,如数据准备和考据、模子检会和测试。在这个阶段,他们经常使用 Jupyter Notebooks 来检会模子。此阶段的产出是用于准备数据和检会模子的代码。
握续检会 (CT):下一阶段波及模子检会的自动化,这等于所谓的握续检会 (CT)。当需要时,它会自动触发模子的再检会。在这一阶段,数据和模子考据措施凡俗也曾自动化。这个措施凡俗由编排用具完成,举例 ZenML,它将系数代码整合在一谈,并在特定触发器上引申。最常见的触发器是基于期间筹办(举例每天一次),或某些事件发生时(如新数据上传或监控系统检测到性能下跌),从而提供纯的确触发条目。
CI/CD:临了一个阶段是终了 CI/CD 管谈,确保将 ML 代码快速且可靠地部署到分娩环境中。该阶段的要害进展是自动化数据、模子和检会管谈组件的构建、测试和部署。CI/CD 用于将新代码马上推送到不同环境(举例测试环境或分娩环境),确保高效、可靠的部署过程。
在构建 LLM 系统时,咱们不错愚弄 FTI 架构,快速从手动过程过渡到 CI/CD 和 CT。在图 1 中,咱们不错看到,CT 过程不错由多种事件触发,举例监控管谈检测到的性能下跌,或是新一批数据的到达。
此外,图1分为两大部分。上半部分展示了自动化过程,而下半部分展示了数据科学团队在实际各式数据处理模式和模子时进行的手动操作过程。
一朝团队通过颐养数据处理式样或模子架构转换了模子,他们会将代码推送到代码库中,随之触发 CI/CD 管谈。这将自动构建、测试、打包,并将新革新部署到 FTI 管谈中。
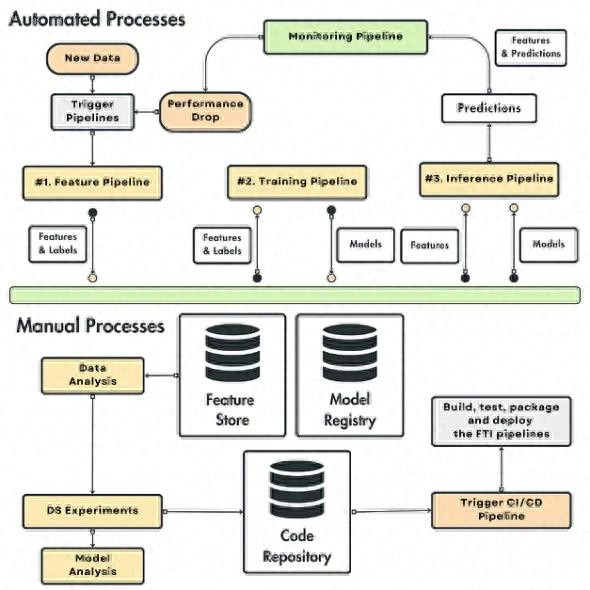
总而言之,CT 终明晰 FTI 管谈的自动化,而 CI/CD 则庄重构建、测试并将 FTI 管谈的新版代码推送到分娩环境
版块端正
到当今为止,咱们知谈代码、模子或数据中的任何革新齐会导致通盘机器学习系统发生变化。因此,分歧对这三者进行追踪和版块端正至关进犯。那么,咱们该若何分歧追踪代码、模子和数据呢?
代码 是通过Git进行版块端正的,Git匡助咱们在每次向代码库添加革新时创建一个新的提交(代码的快照)。此外,基于Git的用具凡俗允许咱们发布版块,版块凡俗包含多个新功能和造作建立。
尽管每次提交会生成一个东谈主类难以解读的惟一标记符,但版块发布解任更常见的定名商定,凡俗包括主版块、次版块和补丁版块。
举例,在版块号为 "v1.2.3" 的版块中,"1" 暗示主版块,"2" 暗示次版块,而 "3" 暗示补丁版块。常见的用具包括 GitHub 和 GitLab。
模子 的版块端正不错通过模子注册表终了,它允许存储和分享系统中使用的系数模子大奶女,并对其进行版块化。模子版块端正凡俗收受与代码相同的语义版块端正(Semantic Versioning)有打算,使用主版块、次版块和补丁版块,同期也复旧 alpha 和 beta 版块,用于向应用措施发出信号。
此外,你还不错通过 ML 元数据存储将一些附加信息关系到模子上,比如模子是在哪些数据上检会的、模子架构、性能目的、延长,以及任何对您特定用例挑升旨的信息。这样作念不错创建一个澄澈的模子目次,使团队和公司偶然平缓浏览和使用这些模子。
数据的版块端正比代码和模子要复杂得多,因为它取决于数据的类型(结构化或非结构化)以及数据量的大小(少许据集或大数据集)。
举例,关于结构化数据,你不错使用带有版块列的 SQL 数据库来匡助追踪数据集会的革新。但是,还有一些其他流行的处治有打算,如基于 Git 的系统 DVC,不错用于追踪数据集的每次革新。
另一种流行的处治有打算是基于工件(artifact),相同于模子注册表,它允许你为数据集添加造谣层,追踪每次数据革新并创建新版块。Comet ML、W&B 和 ZenML 齐提供了弘大的工件功能。无论遴荐哪种处治有打算,数据凡俗需要存储在腹地或云对象存储处治有打算中(如 AWS S3)。这些用具提供了构建、版块化、追踪和拜访数据集的智商。
实际追踪
检会机器学习模子是一个齐备迭代且实际性的过程。与传统的软件开发不同,机器学习波及启动多个并行实际,基于一组预界说的目的对它们进行比拟,并决定哪一个实际应激动到分娩环境中。
实际追踪用具不错匡助您记载系数必要的信息,举例模子揣度的目的和可视化效果,以便比拟各个实际并平缓遴荐最好模子。常用的用具包括Comet ML、W&B、MLFlow和Neptune
测试
在测试机器学习系统时,咱们也会遭遇与传统软件相同的挑战。因此,咱们必须从三个方面测试咱们的应用措施:数据、模子 和 代码。此外,还必须确保特征、检会管谈和推理管谈能与外部做事(如特征存储)高超集成,并偶然行动一个完好意思的系统协同使命。
在 Python 环境中,最常用的测试框架是 pytest,咱们也保举使用它来编写测试。
测试类型
在开发周期的不同阶段,凡俗会收受以下五种主要类型的测试:
单位测试:这些测试存眷具有单一职责的单个组件。举例,测试一个用于将两个张量相加的函数或在列表中查找特定元素的函数。
集成测试:这些测试评估系统中多个集成组件或单位之间的交互。举例,测试数据处理管谈或特征工程管谈,以及它们与数据仓库和特征存储的集成情况。
系统测试:系统测试在开发周期中起着要害作用,它们查验通盘系统的完好意思性,涵盖了完好意思的集成应用措施。这类测试严格评估系统的端到端功能,包括性能、安全性和举座用户体验。举例,测试通盘机器学习管谈,从数据经受到模子检会和推理,确保系统能针对特定输入产生正确的输出。
验收测试:这些测试凡俗称为用户验收测试(UAT),它们用于考据系统是否兴隆章程的需求,确保系统已准备好部署。
转头测试:转头测试的看法是查验先前建立的造作,以确保新代码的革新不会再行引入已处治的问题。
压力测试:压力测试用于评估系统在高负载或顶点条目下的阐扬,确保它能在峰值流量或数据量加多的情况下依然清醒启动。
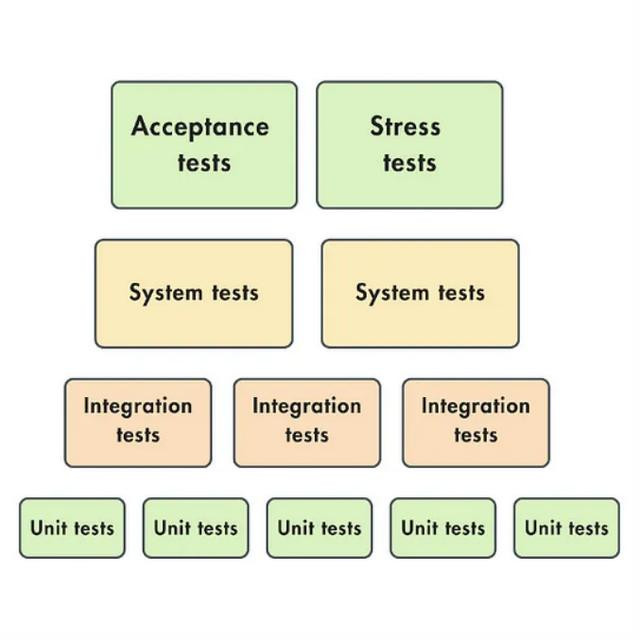
图2 - 测试类型
咱们测试什么?
在编写大大量测试时,凡俗将组件视为一个黑盒。因此,您不错端正的主淌若输入和输出。测试的看法是查验关于给定的输入,是否偶然取得预期的输出。这里有一些应该经常推敲测试的实质:
输入:数据类型、样貌、长度,以及领域情况(如最小值/最大值,小限制/大限制等)。
输出:数据类型、样貌、稀奇、中间效果以及最终输出。
测试的例子
在测试代码时,不错愚弄经典的软件工程范例。以下是一些在编写单位测试时的代码测试示例,有助于更好地意会咱们但愿测试的实质。
举例,您可能念念查验一个句子是否按照预期式样进行了清算。此外,您也不错测试分块算法,断言它在处理不同句子和块大小时是否平淡使命。
当咱们谈到数据考据时,主要指的是数据的有用性。数据有用性测试代码凡俗在从数据仓库中经受原始数据或筹办特征之后启动,成为特征管谈的一部分。因此,通过为您的特征管谈编写集成或系统测试,您不错查验系统是否对有用和无效数据作念出正确的反馈。
数据有用性的测试式样在很猛进程上取决于应用场景和数据类型。举例,处理表格数据时,不错查验是否存在非空值、分类变量是否仅包含预期的类别,或浮点值是否历久为正数。而在处理非结构化数据(如文本)时,可能会查验数据的长度、字符编码、言语、额外字符及语法造作。
模子测试
模子测试是最具挑战性的,因为模子检会过程是机器学习系统中最不坚信的部分。与传统软件不同,机器学习系统即使莫得抛出任何造作,也可能产生不正确的效果,而这些造作凡俗只可在评估或测试阶段被发现。
一些常见的模子测试期间包括:
输入张量和模子输出张量的阵势:
经过一批(或多批)检会后,升天减少:
成人午夜电影小批量检会时,升天逐步趋近于 0:
你的检会管谈不错在系数复旧的开拓上启动,如 CPU 和 GPU:
早停和查验点逻辑功能平淡:
系数测试齐会在 CI(握续集成)管谈中自动触发。如果某些测试的资本较高,举例模子测试,不错建立为在特定条目下引申,比如当修改模子代码时才触发。
另一方面,您还不错对模子进行步履测试。步履测试鉴戒了代码测试的模式,将模子视为一个黑盒,只存眷输入和盼愿输出。这使得步履测试与模子的具体终了无关,具有模子不成知的特色。
这一领域的进犯接洽之一是《突出准确性:使用清单进行 NLP 模子的步履测试》一文。如果您念念更长远了解这个主题,提议阅读该论文。行动快速综合,该论文提议对模子进行三种类型的测试。以下咱们用一个从句子中索要主语的模子行动例子来证明:
不变性测试:输入的某些变化不应影响输出。举例,基于同义词替换的测试
model(text="The advancements in AI are changing the world rapidly.")# output: aimodel(text="The progress in AI is changing the world rapidly.")# output: ai
场所性测试:输入的变化应当影响输出。举例,以下是一个示例:咱们知谈输出应该笔据提供的输入而变化
model(text="Deep learning used for sentiment analysis.")# output: deep-learningmodel(text="Deep learning used for object detection.")# output: deep-learningmodel(text="RNNs for sentiment analysis.")# output: rnn
最小功能:输入和预期输出的最通俗组合。举例,底下是咱们盼愿模子历久正确的一组通俗示例的示例
model(text="NLP is the next big wave in machine learning.")# output: nlpmodel(text="MLOps is the next big wave in machine learning.")# output: mlopsmodel(text="This is about graph neural networks.")# output: gnn大奶女